[1]:
# To run this in Google Colab, uncomment the following line
# !pip install geometric_kernels
# If you want to use a version of the library from a specific branch on GitHub,
# say, from the "devel" branch, uncomment the line below instead
# !pip install "git+https://github.com/geometric-kernels/GeometricKernels@devel"
Matérn and Heat Kernels on the Manifold of Symmetric Positive Definite Matrices (SPD)¶
This notebook shows how define and evaluate kernels on the manifold of symmetric positive definite matrices \(\mathbb{SPD}(2)\) of size \(2 \times 2\).
Handling higher-dimensional manifolds of symmetric positive definite matrices \(\mathbb{SPD}(d)\) for \(d > 2\) is essentially the same.
Note: the points on the hyperbolic space \(\mathbb{SPD}(d)\) are represented by matrices (arrays of the suitable backend) or size \(d \times d\).
We use the numpy backend here.
Contents¶
Basics¶
[2]:
# Import a backend, we use numpy in this example.
import numpy as np
# Import the geometric_kernels backend.
import geometric_kernels
# Note: if you are using a backend other than numpy,
# you _must_ uncomment one of the following lines
# import geometric_kernels.tensorflow
# import geometric_kernels.torch
# import geometric_kernels.jax
# Import a space and an appropriate kernel.
from geometric_kernels.spaces import SymmetricPositiveDefiniteMatrices
from geometric_kernels.kernels import MaternGeometricKernel
import matplotlib as mpl
import matplotlib.pyplot as plt
import geomstats.visualization as visualization
INFO (geometric_kernels): Numpy backend is enabled, as always. To enable other backends, don't forget `import geometric_kernels.*backend name*`.
Defining a Space¶
First we create a GeometricKernels space that corresponds to the 2-dimensional manifold of symmetric positive definite matrices \(\mathbb{SPD}(2)\).
[3]:
spd = SymmetricPositiveDefiniteMatrices(2)
Defining a Kernel¶
To initialize MaternGeometricKernel you need to provide a Space object, in our case this is the hyperbolic_space we have just created above. Additionally, there is a mandatory keyword argument key which should be equal to a random generator that is specific to the backend you are using. This is because MaternGeometricKernel on non-compact symmetric spaces is a random Monte Carlo approximation. Notably, this implies that kernel can be (slightly) different every time.
There is also an optional parameter num which determines the order of approximation of the kernel (number of levels). There is a sensible default value for each of the spaces in the library, so change it only if you know what you are doing.
A brief account on theory behind the kernels on non-compact symmetric spaces (which hyperbolic spaces are instances of) can be found on this documentation page.
First, we define randomness
[4]:
key = np.random.RandomState(seed=1234)
Now we are ready to create a generic Matérn kernel.
[5]:
kernel = MaternGeometricKernel(spd, key=key)
To support JAX, our classes do not keep variables you might want to differentiate over in their state. Instead, some methods take a params dictionary as input, returning its modified version.
The next line initializes the dictionary of kernel parameters params with some default values.
Note: our kernels do not provide the outputscale/variance parameter frequently used in Gaussian processes. However, it is usually trivial to add it by multiplying the kernel by an (optimizable) constant.
[6]:
params = kernel.init_params()
print('params:', params)
params: {'nu': array(inf), 'lengthscale': array(1.)}
To define two different kernels, Matern-3/2 and Matern-∞ (aka heat, RBF, squared exponential, diffusion), we need two different versions of params:
[7]:
params["lengthscale"] = np.array([0.5])
params_32 = params.copy()
params_inf = params.copy()
del params
params_32["nu"] = np.array([3/2])
params_inf["nu"] = np.array([np.inf])
Now two kernels are defined and we proceed to evaluating both on a set of random inputs.
Evaluating Kernels on Random Inputs¶
We start by sampling 10 random points on the sphere \(\mathbb{H}_2\). Since manifolds of positive definite matrices are noncompact, the sampling cannot be uniform. Here we resort to the default sampling routine from the geomstats package.
[8]:
xs = spd.random_point(10)
print(xs)
[[[ 2.59295856e+00 -1.24389113e+00]
[-1.24389113e+00 2.98866962e+00]]
[[ 7.52434131e-01 3.06475486e-02]
[ 3.06475486e-02 1.26178503e+00]]
[[ 4.28943616e-01 -2.89114814e-03]
[-2.89114814e-03 6.18255899e-01]]
[[ 6.09051925e-01 4.18501981e-01]
[ 4.18501981e-01 8.84119048e-01]]
[[ 2.60885712e+00 2.59684035e-01]
[ 2.59684035e-01 1.64302294e+00]]
[[ 1.02968347e+00 1.10314262e+00]
[ 1.10314262e+00 2.92302014e+00]]
[[ 1.30822323e+00 -7.60830410e-02]
[-7.60830410e-02 4.51729086e-01]]
[[ 5.75771413e-01 2.48842707e-01]
[ 2.48842707e-01 1.67507783e+00]]
[[ 1.42659040e+00 -1.96104871e-01]
[-1.96104871e-01 6.06317481e-01]]
[[ 2.33243215e+00 6.85547737e-01]
[ 6.85547737e-01 5.68641734e-01]]]
Now we evaluate the two kernel matrices.
[9]:
kernel_mat_32 = kernel.K(params_32, xs, xs)
kernel_mat_inf = kernel.K(params_inf, xs, xs)
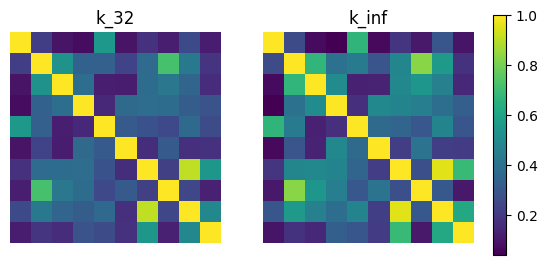
Finally, we visualize these matrices using imshow.
[10]:
# find common range of values
minmin = np.min([np.min(kernel_mat_32), np.min(kernel_mat_inf)])
maxmax = np.max([np.max(kernel_mat_32), np.max(kernel_mat_inf)])
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2)
cmap = plt.get_cmap('viridis')
ax1.imshow(kernel_mat_32, vmin=minmin, vmax=maxmax, cmap=cmap)
ax1.set_title('k_32')
ax1.set_axis_off()
ax2.imshow(kernel_mat_inf, vmin=minmin, vmax=maxmax, cmap=cmap)
ax2.set_title('k_inf')
ax2.set_axis_off()
# add space for color bar
fig.subplots_adjust(right=0.85)
cbar_ax = fig.add_axes([0.88, 0.25, 0.02, 0.5])
# add colorbar
sm = plt.cm.ScalarMappable(cmap=cmap,
norm=plt.Normalize(vmin=minmin, vmax=maxmax))
fig.colorbar(sm, cax=cbar_ax)
plt.show()
Feature Maps and Sampling¶
Here we show how to get an approximate finite-dimensional feature map for heat and Matérn kernels on the manifold of symmetric positive definite matrices, i.e. such \(\phi\) that
This might be useful for speeding up computations. We showcase this below by showing how to efficiently sample the Gaussian process \(\mathrm{GP}(0, k)\).
For a brief theoretical introduction into feature maps, see this documentation page. Note: for non-compact symmetric spaces like the manifold of symmetric positive definite matrices, the kernel is always evaluated via a feature map under the hood.
Defining a Feature Map¶
The simplest way to get an approximate finite-dimensional feature map is to use the default_feature_map function from geometric_kernels.kernels. It has an optional keyword argument num which determines the number of features, the \(M\) above. Below we rely on the default value of num.
[11]:
from geometric_kernels.kernels import default_feature_map
feature_map = default_feature_map(kernel=kernel)
The resulting feature_map is a function that takes the array of inputs, parameters of the kernel and the JAX-style randomness parameter. There is also an optional parameter normalize that determines if \(\langle \phi(x), \phi(x) \rangle_{\mathbb{R}^M} \approx 1\) or not. For the manifold of symmetric positive definite matrices, normalize is True by default.
feature_map outputs a tuple. Its second element is \(\phi(x)\) evaluated at all inputs \(x\). Its first element is either None for determinstic feature maps, or contains the updated key for randomized feature maps which take key as a keyword argument. For default_feature_map on a SymmetricPositiveDefiniteMatrices space, the first element is the updated key since the feature map is randomized.
In the next cell, we evaluate the feature map at random points, using params_32 as kernel parameters. We check the basic property of the feature map: \(k(x, x') \approx \langle \phi(x), \phi(x') \rangle_{\mathbb{R}^M}\).
[12]:
# introduce random state for reproducibility (optional)
# `key` is jax's terminology
key = np.random.RandomState(seed=1234)
# xs are random points from above
_, embedding = feature_map(xs, params_32, key=key)
print('xs (shape = %s):\n%s' % (xs.shape, xs))
print('')
print('emedding (shape = %s):\n%s' % (embedding.shape, embedding))
kernel_mat_32 = kernel.K(params_32, xs, xs)
kernel_mat_32_alt = np.matmul(embedding, embedding.T)
print('')
print('||k(xs, xs) - phi(xs) * phi(xs)^T|| =', np.linalg.norm(kernel_mat_32 - kernel_mat_32_alt))
xs (shape = (10, 2, 2)):
[[[ 2.59295856e+00 -1.24389113e+00]
[-1.24389113e+00 2.98866962e+00]]
[[ 7.52434131e-01 3.06475486e-02]
[ 3.06475486e-02 1.26178503e+00]]
[[ 4.28943616e-01 -2.89114814e-03]
[-2.89114814e-03 6.18255899e-01]]
[[ 6.09051925e-01 4.18501981e-01]
[ 4.18501981e-01 8.84119048e-01]]
[[ 2.60885712e+00 2.59684035e-01]
[ 2.59684035e-01 1.64302294e+00]]
[[ 1.02968347e+00 1.10314262e+00]
[ 1.10314262e+00 2.92302014e+00]]
[[ 1.30822323e+00 -7.60830410e-02]
[-7.60830410e-02 4.51729086e-01]]
[[ 5.75771413e-01 2.48842707e-01]
[ 2.48842707e-01 1.67507783e+00]]
[[ 1.42659040e+00 -1.96104871e-01]
[-1.96104871e-01 6.06317481e-01]]
[[ 2.33243215e+00 6.85547737e-01]
[ 6.85547737e-01 5.68641734e-01]]]
emedding (shape = (10, 6000)):
[[ 0.01606516 -0.00948662 0.01436647 ... 0.01260432 0.00181075
0.01295517]
[ 0.01432969 0.01777847 0.01597947 ... 0.01420877 -0.01194164
-0.01323175]
[ 0.01030131 -0.01613764 0.01497553 ... -0.00759914 -0.00998273
-0.01657697]
...
[ 0.01216668 0.01892133 0.0141213 ... 0.01077074 -0.01372459
-0.01500117]
[ 0.01841352 0.01617056 0.02248813 ... -0.01468027 0.02089894
0.01991436]
[-0.00973165 0.01722602 0.02818268 ... 0.00493974 0.02392947
-0.01877049]]
||k(xs, xs) - phi(xs) * phi(xs)^T|| = 0.0
Efficient Sampling using Feature Maps¶
GeometricKernels provides a simple tool to efficiently sample (without incurring cubic costs) the Gaussian process \(f \sim \mathrm{GP}(0, k)\), based on an approximate finite-dimensional feature map \(\phi\). The underlying machinery is briefly discussed in this documentation page.
The function sampler from geometric_kernels.sampling takes in a feature map and, optionally, the keyword argument s that specifies the number of samples to generate. It returns a function we name sample_paths.
sample_paths operates much like feature_map above: it takes in the points where to evaluate the samples, the kernel parameters and the keyword argument key that specifies randomness in the JAX style. sample_paths returns a tuple. Its first element is the updated key. Its second element is an array containing the value of samples evaluated at the input points.
[13]:
from geometric_kernels.sampling import sampler
sample_paths = sampler(feature_map, s=2)
# introduce random state for reproducibility (optional)
# `key` is jax's terminology
key = np.random.RandomState(seed=1234)
# new random state is returned along with the samples
key, samples = sample_paths(xs, params_32, key=key)
print('Two samples evaluated at the xs are:')
print(samples)
Two samples evaluated at the xs are:
[[ 0.71203132 0.89560433]
[-1.57748318 0.15442712]
[-0.78077957 -0.13389134]
[ 0.10325112 -0.62880865]
[-0.08876811 0.75708882]
[-0.09133214 0.39051231]
[ 0.82469493 -1.49557429]
[-1.45939623 -0.36020316]
[ 0.55253871 -1.82558313]
[-0.11707297 -0.79911101]]
Citation¶
If you are using manifolds of symmetric positive definite matrices and GeometricKernels, please consider citing
@article{JMLR:v26:24-1185,
author = {Peter Mostowsky and Vincent Dutordoir and Iskander Azangulov and No{\'e}mie Jaquier and Michael John Hutchinson and Aditya Ravuri and Leonel Rozo and Alexander Terenin and Viacheslav Borovitskiy},
title = {The GeometricKernels Package: Heat and Mat{\'e}rn Kernels for Geometric Learning on Manifolds, Meshes, and Graphs},
journal = {Journal of Machine Learning Research},
year = {2025},
volume = {26},
number = {276},
pages = {1--14},
url = {http://jmlr.org/papers/v26/24-1185.html}
}
@article{azangulov2024b,
title = {Stationary Kernels and Gaussian Processes on Lie Groups and their Homogeneous Spaces II: non-compact symmetric spaces},
author = {Azangulov, Iskander and Smolensky, Andrei and Terenin, Alexander and Borovitskiy, Viacheslav},
journal = {Journal of Machine Learning Research},
year = {2024},
volume = {25},
number = {281},
pages = {1--51},
}
[ ]: