[1]:
# To run this in Google Colab, uncomment the following line
# !pip install geometric_kernels
# If you want to use a version of the library from a specific branch on GitHub,
# say, from the "devel" branch, uncomment the line below instead
# !pip install "git+https://github.com/geometric-kernels/GeometricKernels@devel"
Bayesian Optimization on the Sphere Manifold \(\mathbb{S}_2\)¶
This notebooks illustrates the application of Bayesian optimization (BO) on a sphere manifold. To run it, you need to have BoTorch installed.
Note: The problem we study below has been intentionally kept very simple to facilitate visualization. As such, do not expect to observe a significant improvement compared to a non-geometric optimization loop. However, in more complex scenarios—such as those involving higher-dimensional manifolds—the advantages of the geometric approach can be substantial, as demonstrated by Jaquier et al. (2022).
[2]:
# Import a backend, we use torch in this example.
import gpytorch
import torch
# Import the geometric_kernels backend.
import geometric_kernels
import geometric_kernels.torch
# Import the Hypersphere space and the general-purpose MaternGeometricKernel
from geometric_kernels.spaces import Hypersphere
from geometric_kernels.kernels import MaternGeometricKernel
# The GPyTorch frontend of GeometricKernels
from geometric_kernels.frontends.gpytorch import GPyTorchGeometricKernel
# For manifold optimization of acquisition functions
import geoopt
from geoopt.optim import RiemannianAdam
# Stuff
import numpy as np
import botorch
import warnings
INFO (geometric_kernels): Numpy backend is enabled. To enable other backends, don't forget to `import geometric_kernels.*backend name*`.
INFO (geometric_kernels): We may be suppressing some logging of external libraries. To override the logging policy, call `logging.basicConfig`.
INFO (geometric_kernels): Torch backend enabled.
[3]:
from packaging.version import Version
if Version(botorch.__version__) < Version("0.7.2"):
from botorch import fit_gpytorch_model
else:
from botorch.fit import fit_gpytorch_mll as fit_gpytorch_model
We initialize a sphere manifold \(\mathbb{S}_2\).
[4]:
sphere = Hypersphere(dim=2)
Define the function to optimize.
Here we use the Ackley function (see, e.g., https://www.sfu.ca/~ssurjano/ackley.html). The function is defined on the tangent space of the base point \((1, 0, 0, ...)\) and projected to the manifold via the exponential map. The value of the function is therefore computed by projecting the point on the manifold to the tangent space of the base point and by computing the value of the Ackley function in this Euclidean space. This requires the logarithmic map on the sphere, also defined below.
[5]:
def logmap(x, x0):
"""
This function maps a point lying on the sphere manifold into the tangent space of a second point on the manifold.
Parameters
----------
:param x: point on the sphere manifold
:param x0: basis point of the tangent space where x will be mapped
Returns
-------
:return: u: vector in the tangent space of x0
"""
if x0.ndim < 2:
x0 = x0[None]
if x.ndim < 2:
x = x[None]
theta = torch.arccos(torch.maximum(torch.minimum(torch.inner(x0, x), torch.ones(1)), -torch.ones(1)))
u = (x - x0 * torch.cos(theta)) * theta / torch.sin(theta)
u[:, torch.where(theta[0] < 1e-16)[0]] = 0.
return u
def ackley_function_sphere(x):
# Data to numpy
if x.ndim < 2:
x = x[None]
# Dimension of the manifold
dimension = x.shape[-1]
# Projection in tangent space of the mean.
# The base is fixed at (1, 0, 0, ...) for simplicity. Therefore, the tangent plane is aligned with the axis x.
# The first coordinate of x_proj is always 0, so that vectors in the tangent space can be expressed in a dimension-1
# dimensional space by simply ignoring the first coordinate.
base = torch.zeros((1, dimension), dtype=x.dtype)
base[0, 0] = 1.
x_proj = logmap(x, base)[0]
# Remove first dim
x_proj_red = x_proj[1:]
reduced_dimension = dimension - 1
# Ackley function parameters
a = 20
b = 0.2
c = 2 * np.pi
# Ackley function
aexp_term = -a * torch.exp(-b * torch.sqrt(torch.sum(x_proj_red ** 2) / reduced_dimension))
expcos_term = - torch.exp(torch.sum(torch.cos(c * x_proj_red) / reduced_dimension))
y = aexp_term + expcos_term + a + np.exp(1.)
return y[None, None]
We also define the routine below for manifold optimization of acquisition functions. It uses geoopt, a library for gradient optimization on manifolds.
[6]:
def optimize_acqf_on_sphere(acq_fct, num_restarts=10, n_steps=50, lr=0.1, device="cpu"):
inits = torch.randn(num_restarts, 3, device=device)
inits = inits / inits.norm(dim=-1, keepdim=True)
best_val = None
best_x = None
for i in range(num_restarts):
x = geoopt.ManifoldParameter(inits[i:i+1].clone().requires_grad_(), manifold=geoopt.manifolds.Sphere())
optimizer = RiemannianAdam([x], lr=lr)
for step in range(n_steps):
optimizer.zero_grad()
val = -acq_fct(x) # minus for "maximize"
val.backward()
optimizer.step()
final_val = acq_fct(x).item()
if (best_val is None) or (final_val > best_val):
best_val = final_val
best_x = x.detach().clone()
return best_x, best_val
Initialization¶
Generate 5 random data locations on the sphere to be used as initial design for BO.
[7]:
nb_data_init = 5
key = torch.Generator()
key.manual_seed(1234)
key, x_data = sphere.random(key, nb_data_init)
y_data = torch.zeros(nb_data_init, dtype=torch.float64)
for n in range(nb_data_init):
y_data[n] = ackley_function_sphere(x_data[n])
print('Inputs:', x_data)
print('Outputs: ', y_data)
Inputs: tensor([[ 0.0423, 0.3693, -0.9283],
[ 0.2637, -0.7450, 0.6128],
[ 0.2970, 0.8911, -0.3431],
[ 0.9919, 0.0465, -0.1179],
[-0.1118, -0.9892, -0.0952]], dtype=torch.float64)
Outputs: tensor([6.1984, 3.9993, 5.2496, 0.7422, 5.9154], dtype=torch.float64)
Definition of the BO Surrogate Model¶
Here we use a Gaussian process with a Matérn kernel on \(\mathbb{S}_2\).
The kernel has three positive real hyperparameters: variance \(\sigma^2\), length scale \(\kappa\) and smoothness \(\nu\). Defining a Gaussian process model also requires a likelihood noise hyperparameter \(\sigma_n^2\).
We use the \(\operatorname{Gamma}(2.0, 0.15)\) prior for \(\sigma\), the square root of \(\sigma^2\), and \(\operatorname{Gamma}(1.1, 0.05)\) prior for \(\sigma_n^2\).
We first define the kernel.
[8]:
base_kernel = GPyTorchGeometricKernel(MaternGeometricKernel(sphere))
kernel = gpytorch.kernels.ScaleKernel(base_kernel,
outputscale_prior=gpytorch.priors.torch_priors.GammaPrior(2.0, 0.15))
We then define the likelihood of the Gaussian process.
[9]:
noise_prior = gpytorch.priors.torch_priors.GammaPrior(1.1, 0.05)
noise_prior_mode = (noise_prior.concentration - 1) / noise_prior.rate
lik_fct = gpytorch.likelihoods.gaussian_likelihood.GaussianLikelihood(noise_prior=noise_prior,
noise_constraint=
gpytorch.constraints.GreaterThan(1e-8),
initial_value=noise_prior_mode)
We finally initialize the GP model, as well as the marginal likelihood function that will be used to optimize its parameters.
[10]:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
model = botorch.models.SingleTaskGP(x_data, y_data[:, None], covar_module=kernel, likelihood=lik_fct)
mll_fct = gpytorch.mlls.ExactMarginalLogLikelihood(model.likelihood, model)
Bayesian optimization loop¶
[11]:
new_best_f, index = y_data.min(0)
best_x = [x_data[index]]
best_f = [new_best_f]
Now we define the shorthand for acquisition optimization. In the next cell, you can also choose to use non-manifold optimization of acquisitions.
[12]:
def ack_optimize(acq_fct, num_restarts=10):
return optimize_acqf_on_sphere(acq_fct, num_restarts=num_restarts, n_steps=50, lr=0.1, device=x_data.device)
# (Un)comment below if you (don't) want to use manifold optimization of acquisitions
# # We define the bounds for the optimization of the acquisition function, as well as the constraints that must be satisfied by candidate points on the sphere.
# bounds = torch.stack([-torch.ones(3, dtype=torch.float64), torch.ones(3, dtype=torch.float64)])
# def upper_constraint(x):
# return 1.0 - torch.linalg.norm(x, dim=-1)
# def lower_constraint(x):
# return torch.linalg.norm(x, dim=-1) - 1.0
# def ack_optimize(acq_fct, num_restarts=10):
# # this uses constrained optimization on the sphere to guarantee that our new candidate point belongs to the sphere manifold
# return botorch.optim.optimize_acqf(acq_fct, bounds=bounds, q=1,
# num_restarts=num_restarts, raw_samples=100,
# nonlinear_inequality_constraints=[upper_constraint,
# lower_constraint],
# batch_initial_conditions=batch_initial_conditions[:, None])
Finally, we can run our BO loop. At each iteration, we first optimize our GP model, then we define the acquisition function, and select the new candidate point as the point maximizing the acquisition function.
[13]:
n_iters = 15
[14]:
for iteration in range(n_iters):
# Fit GP model
fit_gpytorch_model(mll=mll_fct)
# Define the acquisition function
acq_fct = botorch.acquisition.ExpectedImprovement(model=model, best_f=best_f[-1], maximize=False)
# Initial conditions to optimize the acquisition function
key, batch_initial_conditions = sphere.random(key, 100)
batch_initial_conditions /= torch.linalg.norm(batch_initial_conditions, dim=-1)[:, None]
# Get new candidate
with warnings.catch_warnings():
warnings.simplefilter("ignore")
new_x, acq_new_x = ack_optimize(acq_fct, num_restarts=25)
# Get new observation
new_y = ackley_function_sphere(new_x)[0]
# Update training points
x_data = torch.cat((x_data, new_x))
y_data = torch.cat((y_data, new_y))
# Update best observation
new_best_f, index = y_data.min(0)
best_x.append(x_data[index])
best_f.append(new_best_f)
# Update the model
model.set_train_data(x_data, y_data, strict=False) # strict False necessary to add datapoints
print("Iteration " + str(iteration+1) + "\t Best f " + str(new_best_f.item()))
Iteration 1 Best f 0.7421870944514706
Iteration 2 Best f 0.7421870944514706
Iteration 3 Best f 0.7421870944514706
Iteration 4 Best f 0.3548612594604492
Iteration 5 Best f 0.3548612594604492
Iteration 6 Best f 0.3548612594604492
Iteration 7 Best f 0.3548612594604492
Iteration 8 Best f 0.08060359954833984
Iteration 9 Best f 0.08060359954833984
Iteration 10 Best f 0.08060359954833984
Iteration 11 Best f 0.08060359954833984
Iteration 12 Best f 0.08060359954833984
Iteration 13 Best f 0.08060359954833984
Iteration 14 Best f 0.06093120574951172
Iteration 15 Best f 0.06093120574951172
[15]:
x_eval = x_data.cpu().numpy()
y_eval = y_data.cpu().numpy()[:, None]
best_x_np = np.array([x.cpu().detach().numpy() for x in best_x])
best_f_np = np.array([f.cpu().detach().numpy() for f in best_f])[:, None]
Results¶
[16]:
import matplotlib.pyplot as plt
import matplotlib.pylab as pl
from mpl_toolkits.mplot3d import Axes3D
We set the true minimum value of the objective function to evaluate the performance of the BO.
[17]:
true_min_x = np.zeros((1, 3))
true_min_x[0, 0] = 1.
true_min_value = 0.0
We display the candidate points on the sphere evaluated in the BO loop. Their color indicate the value of the function (yellow is low, purple is high). The best candidate is displayed as a red diamond, and the true minimum as a blue cross.
[18]:
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(111, projection="3d")
# Make the panes transparent
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
# Make the grid lines transparent
ax.xaxis._axinfo["grid"]['color'] = (1, 1, 1, 0)
ax.yaxis._axinfo["grid"]['color'] = (1, 1, 1, 0)
ax.zaxis._axinfo["grid"]['color'] = (1, 1, 1, 0)
# Remove axis
ax._axis3don = False
# Initial view
ax.view_init(elev=10, azim=30.)
# Plot sphere
n_elems = 100
r = 0.99
u = np.linspace(0, 2 * np.pi, n_elems)
v = np.linspace(0, np.pi, n_elems)
x = r * np.outer(np.cos(u), np.sin(v))
y = r * np.outer(np.sin(u), np.sin(v))
z = r * np.outer(np.ones(np.size(u)), np.cos(v))
ax.plot_surface(x, y, z, rstride=4, cstride=4, color=[0.8, 0.8, 0.8], linewidth=0, alpha=0.4)
lim = 1.1
ax.set_xlim3d([-lim, lim])
ax.set_ylim3d([-lim, lim])
ax.set_zlim3d([-0.75*lim, 0.75*lim])
# Plot evaluated points
max_colors = np.max(y_eval - true_min_value)
for n in range(x_eval.shape[0]):
ax.scatter(x_eval[n, 0], x_eval[n, 1], x_eval[n, 2], s=50,
c=pl.cm.inferno(1. - (y_eval[n] - true_min_value) / max_colors))
# Plot true minimum
ax.scatter(true_min_x[0, 0], true_min_x[0, 1], true_min_x[0, 2], s=200, c='b', marker='P')
# Plot BO minimum
ax.scatter(best_x_np[-1][0], best_x_np[-1][1], best_x_np[-1][2], s=100, c='r', marker='D')
plt.show()
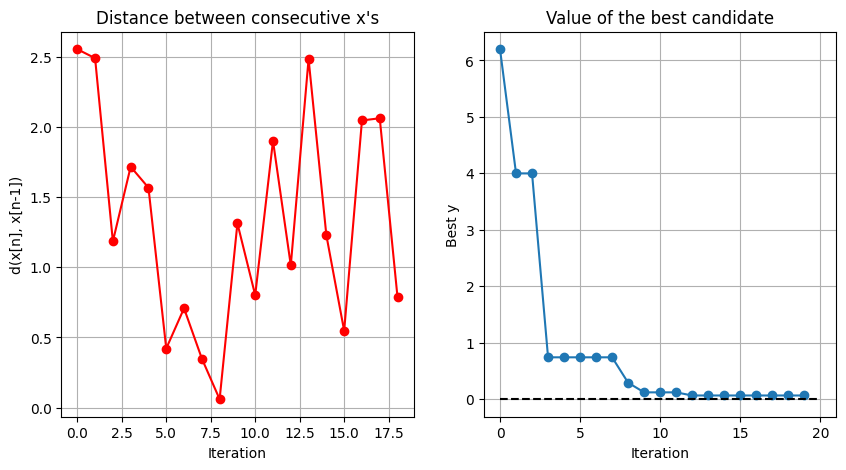
We finally display the distance between consecutive candidate points on the sphere, and the convergence plot of our BO algorithm.
[19]:
def sphere_distance(x, y):
if np.ndim(x) < 2:
x = x[:, None]
if np.ndim(y) < 2:
y = y[:, None]
# Compute the inner product (should be [-1,1])
inner_product = np.dot(x.T, y)
inner_product = np.max(np.min(inner_product, 1), -1)
return np.arccos(inner_product)
# Compute distances between consecutive x's and best evaluation for each iteration
neval = x_eval.shape[0]
distances = np.zeros(neval-1)
for n in range(neval-1):
distances[n] = sphere_distance(x_eval[n + 1, :], x_eval[n, :])
Y_best = np.ones(neval)
for i in range(neval):
Y_best[i] = y_eval[:(i + 1)].min()
# Plot distances between consecutive x's
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(np.array(range(neval - 1)), distances, '-ro')
plt.xlabel('Iteration')
plt.ylabel('d(x[n], x[n-1])')
plt.title('Distance between consecutive x\'s')
plt.grid(True)
# Plot value of the best candidate
plt.subplot(1, 2, 2)
plt.plot(np.array(range(neval)), Y_best, '-o')
plt.hlines(true_min_value, 0, neval, 'k', '--')
plt.title('Value of the best candidate')
plt.xlabel('Iteration')
plt.ylabel('Best y')
plt.grid(True)
plt.show()

Citation¶
If you are using Bayesian optimization and GeometricKernels, please consider citing
@article{JMLR:v26:24-1185,
author = {Peter Mostowsky and Vincent Dutordoir and Iskander Azangulov and No{\'e}mie Jaquier and Michael John Hutchinson and Aditya Ravuri and Leonel Rozo and Alexander Terenin and Viacheslav Borovitskiy},
title = {The GeometricKernels Package: Heat and Mat{\'e}rn Kernels for Geometric Learning on Manifolds, Meshes, and Graphs},
journal = {Journal of Machine Learning Research},
year = {2025},
volume = {26},
number = {276},
pages = {1--14},
url = {http://jmlr.org/papers/v26/24-1185.html}
}
@inproceedings{jaquier2022,
title={Geometry-aware Bayesian optimization in robotics using Riemannian Matérn kernels},
author={Jaquier, Noémie and Borovitskiy, Viacheslav and Smolensky, Andrei and Terenin, Alexander and Asfour, Tamim and Rozo, Leonel},
booktitle={Conference on Robot Learning},
year={2022},
}
[ ]: